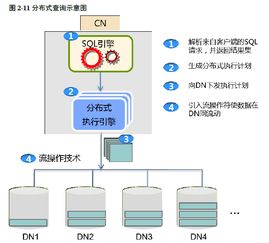
在當今數據驅動的商業環境中,數據服務已成為企業運營和決策的核心支撐。其中,數據處理和存儲支持服務構成了數據服務體系中至關重要的一類。本文旨在系統梳理這一服務分類,并結合業界實踐(如CSDN等技術社區中常見的討論與應用場景)進行闡述,以明晰其內涵、價值與關鍵技術。
一、數據處理與存儲支持服務的定義與范疇
數據處理與存儲支持服務,主要指為原始數據提供加工、整合、管理以及持久化保存的一系列技術能力與解決方案。其核心目標是確保數據從產生到最終被分析利用的全過程中,具備可用性、完整性、安全性與高性能。這類服務通常不直接提供數據分析洞見,而是為上層的數據分析、機器學習、應用開發等構建堅實、高效的“數據基座”。
其核心范疇包括:
- 數據存儲服務:提供數據的持久化存放能力。這包括:
- 數據庫服務:關系型數據庫(如MySQL、PostgreSQL托管服務)、NoSQL數據庫(如文檔數據庫MongoDB、寬列存儲Cassandra、鍵值存儲Redis)、圖數據庫等。
- 數據倉庫服務:面向分析、支持大規模數據存儲和復雜查詢的集中式存儲,如Snowflake、Amazon Redshift、Google BigQuery的托管服務。
- 數據湖存儲:用于存儲原始格式(結構化、半結構化、非結構化)海量數據的存儲庫,如基于對象存儲(如AWS S3、阿里云OSS)構建的數據湖。
- 備份與歸檔存儲:提供成本更低、長期安全的數據備份與冷數據歸檔解決方案。
- 數據處理服務:提供數據的移動、轉換、清洗與加工能力。這包括:
- 數據集成與ETL/ELT服務:將數據從各種源頭(業務系統、日志、IoT設備等)抽取、轉換并加載到目標存儲中。現代服務更傾向于ELT(先加載后轉換),以利用云數據倉庫的強大計算能力。
- 流數據處理服務:實時處理連續不斷的數據流,如使用Apache Kafka、Apache Flink或AWS Kinesis等托管服務進行實時過濾、聚合與轉換。
- 批量數據處理服務:對海量歷史數據進行周期性、大規模的清洗、轉換與計算,通常基于Hadoop、Spark等框架的云托管服務。
- 數據清洗與質量服務:識別并修正數據中的錯誤、不一致和重復項,確保數據質量。
二、核心價值與業務驅動
企業選擇專業化數據處理與存儲支持服務,主要受以下價值驅動:
- 降低技術復雜度與運維成本:云服務商提供的全托管服務(如Amazon RDS、Azure SQL Database、阿里云MaxCompute)讓企業無需關心底層服務器、存儲擴容、軟硬件故障修復與性能調優,可以專注于業務邏輯開發。這在CSDN等開發者社區中是頻繁被討論的“上云”核心優勢之一。
- 實現彈性可擴展與高性能:服務可根據數據量和計算需求自動彈性伸縮,輕松應對業務峰值(如電商大促),并按實際使用量付費,優化成本。高性能的托管存儲與計算引擎保障了數據查詢與處理的效率。
- 保障數據安全與合規:專業服務提供商通常內置了強大的安全功能,如網絡隔離、加密(傳輸中與靜態)、訪問控制、審計日志以及符合GDPR、等保等法規要求的合規性認證,減輕了企業的合規負擔。
- 加速數據價值變現:通過高效、可靠的數據管道,將原始數據快速轉化為可供分析的、高質量的可用數據,顯著縮短了從數據產生到產生業務洞察的周期,支持敏捷決策。
三、關鍵技術趨勢與選型考量
結合CSDN等技術社區的實踐分享,當前該領域呈現以下趨勢與選型要點:
- 云原生與Serverless化:服務愈發以云原生方式交付,特別是Serverless架構(如AWS Aurora Serverless、Google BigQuery)正成為主流。它實現了細粒度的自動擴縮容和真正的按需付費,進一步降低了運維門檻和資源閑置成本。
- 存算分離與湖倉一體:將存儲與計算資源解耦,允許它們獨立擴展,提升了資源利用率和靈活性。“湖倉一體”架構(如Databricks Lakehouse)正在融合數據湖的靈活性與數據倉庫的管理分析能力,成為新一代數據架構的核心。
- 實時化能力成為標配:業務對實時響應的需求推動流處理服務從“可選”變為“必選”。能夠同時支持批流一體處理的框架和服務(如Apache Flink的托管服務)備受青睞。
- 智能化與自動化運維:服務內置的智能監控、自動性能調優、故障預測與自愈能力,正在將數據工程師從繁重的運維工作中解放出來。
選型考量:企業在選擇具體服務時,需綜合評估自身的數據規模、結構、處理延遲要求(實時/準實時/批處理)、現有技術棧、團隊技能、安全合規要求以及總體擁有成本(TCO)。社區(如CSDN)中的案例評測、性能對比和踩坑經驗分享,是重要的參考依據。
###
數據處理與存儲支持服務是數據價值鏈中不可或缺的“基石”環節。它通過專業化、平臺化和服務化的方式,將復雜的技術挑戰轉化為可便捷使用的資源,從而賦能企業高效、安全地管理和加工數據燃料。隨著云原生、Serverless、湖倉一體等技術的持續演進,這類服務正朝著更智能、更彈性、更融合的方向發展,為各行業的數字化轉型提供更強大的底層動力。對于開發者和架構師而言,深入理解并合理運用這些服務,是構建現代數據能力的關鍵一步。